权威解析


24小时热点

特朗普为什么决定不来北京出席阅兵 面子与利益的纠结
2025-08-10 16:48:53
花莲蓝营民代怒批民进党 史上最失败贸易谈判
2025-08-10 12:24:00
一切让人眼花缭乱
2025-08-08 09:30:27
巴防长回呛印度:公开各自飞机库存 质疑印方说法真实性
2025-08-10 13:55:48
学者:莫迪的访华之行注定不轻松 多边舞台上的微妙平衡
2025-08-07 20:40:17
美媒为何称歼-10CE更适合伊朗 性价比与技术优势明显
2025-08-09 21:11:12
专家观点









DeepSeek砸开裂缝 国产算力奔涌而出 开启并行供应线
DeepSeek成为国产算力企业在春节期间的一大亮点。2025年春节前,DeepSeek发布了大模型;春节期间,国内GPU企业和云计算厂商纷纷披露适配DeepSeek模型的进展,许多科技从业者因此度过了一个忙碌的假期。DeepSeek大模型基于英伟达的GPU进行训练,目前后者在全球大模型算力中占据主导地位。然而,DeepSeek也暗示了一种可能性:训练高性能的大模型可能不需要如此高的算力投入。
DeepSeek在科技圈引起轰动,为国产算力与国产大模型结合提供了机会。沐曦CTO杨建预测,到今年年底部分大模型的预训练可能会转向非英伟达的芯片,这一趋势将在明年更加明显。他认为中国市场将逐渐演变,最终形成英伟达和其他国产芯片并行的两条算力供应线。
春节期间,多家国产芯片企业密集适配DeepSeek。例如,硅基流动公司宣布其自研推理加速引擎使华为云昇腾云服务部署的DeepSeek模型达到高端GPU的效果。Gitee AI则表示,在春节期间上线了四个较小尺寸的DeepSeek模型,这些模型均部署在沐曦曦云GPU上。摩尔线程也在其自主设计的夸娥GPU集群上完成了小尺寸DeepSeek模型的部署,并计划开放夸娥智算集群支持更多模型的分布式部署。优刻得基于壁仞科技的国产芯片开展包括R1在内的DeepSeek全系列模型适配工作。昆仑芯也完成了全版本模型适配,其中包括DeepSeek MoE 模型及其蒸馏的小模型。
尽管这些中国芯片企业积极适配DeepSeek,但目前全球主要科技大厂如阿里云、百度云、腾讯云以及亚马逊云科技等仍以英伟达作为主要算力底座。杨建和王晓慧都认为,目前全球98%以上的训练仍然依赖于英伟达的GPU。
DeepSeek展示了强大的产业穿透力,但并未完全脱离英伟达生态。王华指出,DeepSeek的技术实现依然深度依赖NVIDIA的核心组件(PTX)。即使框架层试图抽象化CUDA API,只要底层运行在英伟达GPU上,就不可避免地与CUDA工具链和硬件驱动绑定。
王晓慧认为,虽然国产算力成功运行DeepSeek模型是重要的一步,但要实现更好的性能还需要解决诸多挑战。例如,如何更好地结合模型架构和硬件架构,提高整体性能。此外,国产芯片需要在价格上提供更大的折扣才能吸引更多私有化部署的企业。
美国对高端算力芯片的禁令加剧了中国企业获取英伟达产品的难度,这也促使中国芯片企业加快自主研发。王晓慧表示,未来中国算力的发展是必然趋势,国产算力的提升将逐步降低单一依赖风险。随着时间和技术积累,未来的算力底座更可能呈现多元共存的形态。(责任编辑:于浩淙 zx0176)
精选推荐

“九三阅兵”首次演练画面公布 踢正步背后的血汗史诗
2025-08-11 07:34:01
以军炸死记者 众人怒吼将遗体抬出 维和英雄血染蓝盔
2025-08-11 08:41:47
3年多了,形势大逆转:最新民调结果,给了乌克兰一记重锤
2025-08-11 08:20:27
印度为何此时披露曾击落巴方6架军机 迟来声明引争议
2025-08-11 07:09:49
记者:印度连出三招反制美国 军购暂停、能源反击、外交转向
2025-08-11 08:46:10
记者称印度连出三招反制美国 莫迪强硬回应贸易威胁
2025-08-11 08:43:45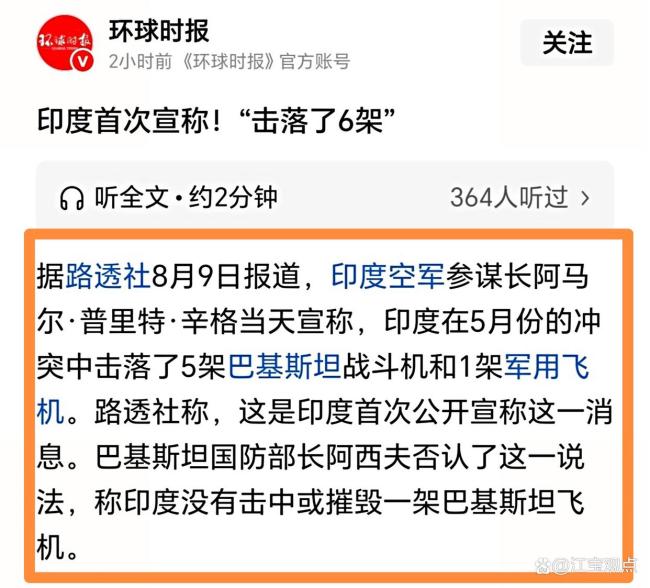
专家:印称击落6架巴军机难圆其说 双方信息战再起波澜
2025-08-11 08:59:06
可汗战机凭啥拿下印尼埃及大单 三大因素揭秘
2025-08-11 09:44:49
泽连斯基拒当美俄交易牺牲品说明啥 争取入局机会
2025-08-11 07:13:37
俄军导弹从天而降 20名乌士兵身亡 斩首战升级
2025-08-11 09:44:11